
“完全搞不懂这种验证码有什么作用,看起来我随便写个脚本就能破解。”
一个闲得发毛的下午,K神如是说道。
点击式验证码
刚才展示的动图是 Google 的一款验证码 (CAPTCHA) 系统,用以替代恼人的传统字符型验证码 (text CAPTCHAs)。
类似的还有滑块式解锁,滑块+拼图式。这些看起来比字符型验证码更加简单的方法,实际上使用的信息不仅仅是一次点击这么简单。
Google 用来获取用户数据的 js 脚本是经过混淆的,基于虚拟机的,甚至周期性更新的。但是仍然有人成功破解过:
https://github.com/neuroradiology/InsideReCaptcha
这人曾经反向工程了 Google 的新验证码系统,并简单描述了在这种验证码中,一次点击所给出的信息:
Google servers will receive and process, at least, the following information:
- Plug-ins
- User-agent
- Screen resolution
- Execution time, timezone
- Number of click/keyboard/touch actions in the
<iframe>of the captcha- It tests the behavior of many browser-specific functions and CSS rules
- It checks the rendering of canvas elements
- Likely cookies server-side (it’s executed on the www.google.com domain)
- And likely other stuff…
You can look at the decompiled bytecode for more precision.
This information, along with numeric values hardcoded in the bytecode (forcing a potential bot to read all of it), is sent to the
https://www.google.com/recaptcha/api2/framepage. Look at theM.prototype.Qfunction to see how the encoding process is realized. Some of information (the one I callxhr2in the decompiler, which is retrieved in thethis.c[this.g]variable −xhr1is inthis.c[this.d]) is also encrypted with XTEA.
对于一个正常使用的用户来说,单纯的一次点击明显要比从键盘输入一些难懂的字符要轻松的多,尤其是在移动设备上。有人可能担心这种验证码是否会过于容易被破解,而以上的反向工程信息应该会让这类人放心一下。
好吧也许并不会。会有这种担心的人一开始就不会理解 Google 对于 js 加密的丧心病狂的偏执,大概也不会理解上面的内容。
滑动拼图式验证码
实现思路
很多互联网服务逐渐采用的一个方式,比如K神吐槽的就是B站那款。
看起来是“把拼图滑动到准确的位置”这种验证,但是后台实现千差万别。
有的是单纯验证拼图准确度,最低级的一种;
稍微高级一点的会收集用户动作轨迹,用神经网络之类的检测行为;
再高级一点的,会跟上文的点击式验证码一样,同时收集用户广泛的信息并判断。
还有超一流的实现方法,主要思路是做好看的 PPT,然后被打脸的时候忍住别喊疼:
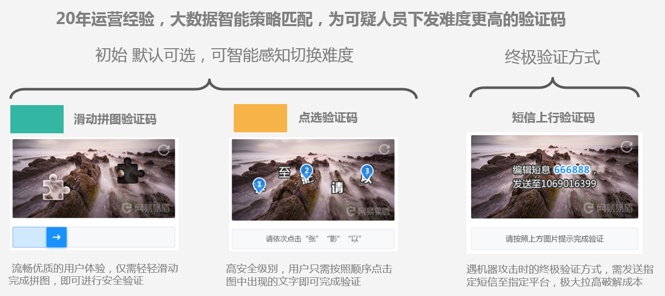
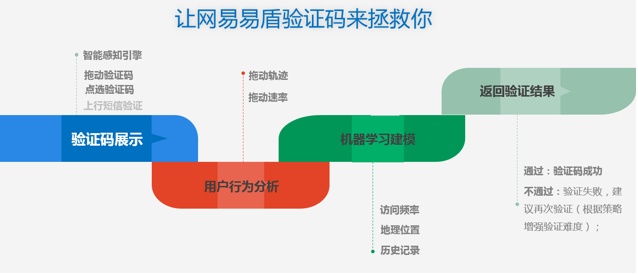
破解思路
大部分人想到的恐怕是sikuli或者按键精灵wwwww
高级一点的思路是 Selenium
有实力的会直接考虑逆向js,就算是 Google 的前端 js 也不是没人逆向出来不是么…虽然几周之后也就失效了因为 Google 又更新了它的虚拟机….
敬畏之心
一个知乎回答是这么说的:
滑块验证码,这玩意,根本就不是为了提高安全性而做出来的。相反,他是为了在不明显降低安全性的前提下,让验证码对人类更加友好。
不可否认很多滑动式验证码的现状的确是这样的。
但是考虑到初衷,从一个字符串,到一个滑动的动作,其中反馈的信息量以及模仿成本是在增长的。没有利用好可获得的信息进行判断是厂商解决方案的幼稚,但是信息量更大的操作来替代信息贫乏的操作这一思路大体上还是明智的。设计一个验证码系统,主要考虑三件事情:
- 让用户操作变得简单
- 让破解成本增加
- 让资源开销降低
对于验证码系统,以及围绕其展开的攻防升级本质上对破解成本的升级与用户易用性的妥协。传统图形字符串验证码的破解成本目前仍然比一些简单实现的滑块式验证码高出不少(传统验证码主要破解思路是预处理+pytesseract,或者直接暴力tensorflow),但是对于诸如 Google 维护的 reCAPTCHA 系统来讲,想要维护一个破解方案以长时间应对周期性变动的js虚拟机显然是一件劳民伤财的事情。
插播一小段更新
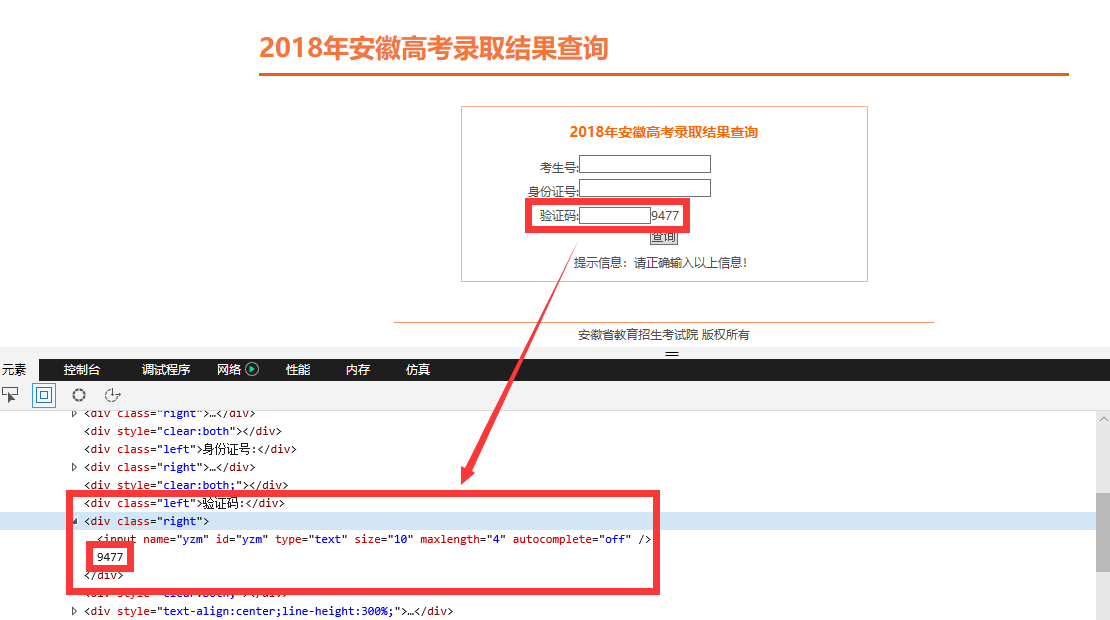
拓展阅读:
https://github.com/neuroradiology/InsideReCaptcha
https://www.improgrammer.net/robot-introducing-no-captcha-recaptcha/
I am not a robot: Google swaps text CAPTCHAs for quivery mouse clicks
https://www.zhihu.com/question/32209043
http://www.360doc.com/content/17/0623/11/5315_665775043.shtml
https://www.zhihu.com/question/51198806